Learning Simple Sentences
In which I make an interactive demo of word sequence learning with HTM, with an eye to how generalisation might happen. I find some generalisation through word representations mixing their feed-forward receptive fields. This occurs because I bias column activations to depolarised cells. Of course this is only a superficial start at looking at generalisation.
On Rob Freeman’s insistence I’ve made up a demo of word sequence learning in HTM. I was resistant because I thought generalisation in language was inextricably tied up with the semantic content of the concepts involved. Rob suggested just “babbling” with some arbitrary words and looking at how generalisation might happen nonetheless. I am still not entirely convinced, but it is intriguing.
So I made up some simple sentences which share context. Each sentence is presented as a sequence of words, where each word is given a unique representation completely unrelated to the other words. This is in contrast to the approach of cortical.io, which represents semantic overlap between words in their encoding for input to HTM (not that I know anything much about it).
> Jane has eyes . > Jane has a head . > Jane has a mouth . > Jane has a brain . > Jane has a book . > Jane has no friend . > Chifung has eyes . > Chifung has a head . > Chifung has a mouth . > Chifung has a brain . > Chifung has no book . > Chifung has a friend .
Although these sentences sound as if they come from a logic system, remember that HTM is seeing just a sequence of meaningless tokens. The words are to help us think about what kinds of generalisation might be reasonable. As an input stream, the above is exactly equivalent to:
V X Y Z O V X Y A B O V X Y A C O V X Y A D O V X Y A E O V X Y F G O V H Y Z O V H Y A B O V H Y A C O V H Y A D O V H Y F E O V H Y A G O
To me it seems reasonable to generalise on these sequences such that
when it gets to “Chifung has a”, before brain, then brain and
book could be predicted as possible options (along with head and
mouth). This is generalisation because it would never have seen the
exact sequence “Chifung has a brain” before.
Some technical details with the input. I present each sentence 3 times so that synapses can learn enough to become connected. I start by presenting the words “Jane” and “Chifung” on their own to stabilise their feed-forward receptive fields. Sentences are separated by a gap (a time step with no input at all), which allows the next sequence to start fresh, without continuous context. It is useful to include a start token (“>”) and end token (“.”) on each, so that words can have a specific representation for starting a sentence, and so the end of a sentence can be predicted.
Predictions and votes
How can we extract predictions from HTM in terms of the source input words? Start with the set of cells in the predictive state. Through their columns, trace back their proximal synapses connected to the encoded input bit array. This gives a number of votes (number of connected synapses) for each input bit. Going over each possible word, work out the percentage of votes falling in that word’s bit-set, and the average number of votes over the word’s complete bit-set. (These would only give different orderings if the inputs were of different sizes).
Play with it
Here’s the interactive demo. You also have the option to enter your own input!
Note: Maximise browser window before loading page. Google Chrome browser recommended.
Results
Here are some highlights of the above demo using my default parameter values.
First, a very basic sort of generalisation can be seen as a
consequence of bursting. Columns burst when they are activated by
input they didn’t predict. In that case all cells in the columns
become active, and consequently, predictions are made from that input
in any previous context. For example, when first presented with
“Chifung has”, that “has” is bursting and so opens up the
previously-learned associations (see Predictions at the bottom
left):

However, that generalisation is short-lived, since as soon as the
transition “Chifung has” is learned, it gets its own representation
and is no longer bursting (note no predictions this time):

A curious thing happens a little later on. Some generalisation appears
to happen, specifically brain and book come up as predictions when
they haven’t been seen in the context before:
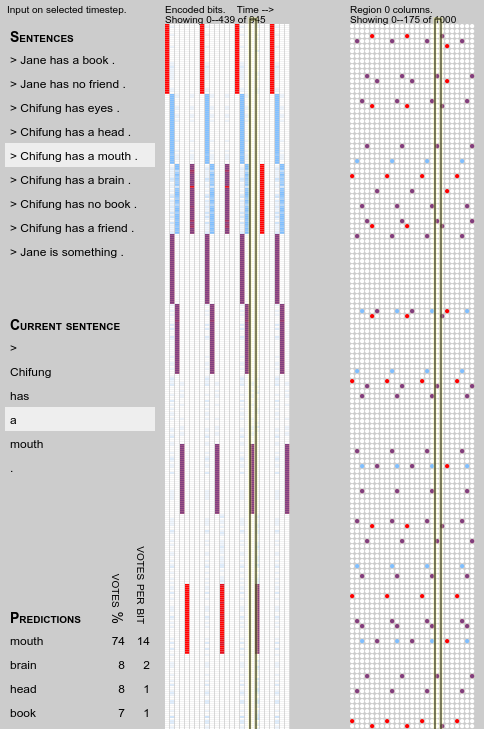
Note that the predictions are fairly light, at only 1 to 2 votes per
bit, so not enough to stop the transition from bursting on first
exposure to an actual input of “brain”.
These predictions are a result of the columns representing “mouth”
overlapping—and thus sharing feed-forward synapses with—those
representing “brain”, “head” and “book”:
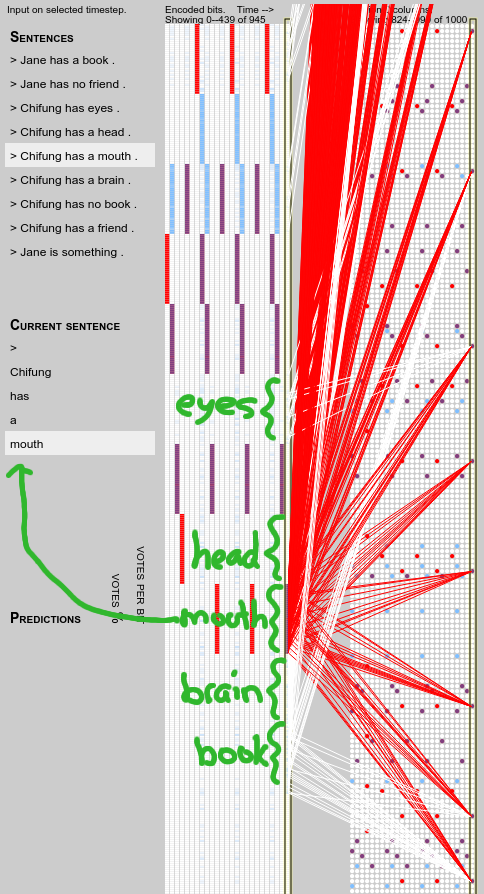
So, how did that arise? Well, a recently added feature in my code is
to bias columns containing predicted (depolarised) cells to become
active; an idea I got from Fergal
Byrne.
When the representation of “mouth” was first formed in “Jane has a
mouth”, the columns/cells for “head” were being predicted, and
consequently some became active. Since active columns adapt their
input fields to the current input, this led to the overlap in
representations. Similarly the later inputs “brain” and “book”
appeared when "mouth" was predicted and so ended up overlapping with
it.
I tested this by turning off the biasing behaviour
(proximal-vs-distal-weight=10000, global-inhibition=true), and
sure enough the phenomenon did not occur.
Here is another example of this phenomenon, this time generalising the
prediction of “book” to “mouth” and “brain”:

Parameters
While all parameters are listed in the code, I’ve reproduced the descriptions of the relevant ones here, together with their default values in the demo.
You can change them in the interactive demo and of course I encourage you to do so.
Proximal synapses and columns
-
column-dimensions = [1000]- size of column field as a vector, one dimensional[size]or two dimensional[width height]. -
ff-potential-radius = 1.0- range of potential feed-forward synapse connections, as a fraction of the longest single dimension in the input space. -
ff-potential-frac = 0.3- fraction of inputs within range that will be part of the potentially connected set. -
ff-perm-inc = 0.05- amount to increase a synapse’s permanence value by when it is reinforced. -
ff-perm-dec = 0.01- amount to decrease a synapse’s permanence value by when it is not reinforced. -
ff-perm-connected = 0.20- permanence value at which a synapse is functionally connected. Permanence values are defined to be between 0 and 1. -
ff-stimulus-threshold = 3- minimum number of active input connections for a column to be overlapping the input (i.e. active prior to inhibition).
Distal synapses and sequence memory
-
depth = 8- number of cells per column. -
max-segments = 5- maximum number of segments per cell. -
seg-max-synapse-count = 18- maximum number of synapses per segment. -
seg-new-synapse-count = 12- number of synapses on a new dendrite segment. -
seg-stimulus-threshold = 9- number of active synapses on a dendrite segment required for it to become active. -
seg-learn-threshold = 7- number of active synapses on a dendrite segment required for it to be reinforced and extended on a bursting column. -
distal-perm-inc = 0.05- amount by which to increase synapse permanence when reinforcing dendrite segments. -
distal-perm-dec = 0.01- amount by which to decrease synapse permanence when reinforcing dendrite segments. -
distal-perm-connected = 0.20- permanence value at which a synapse is functionally connected. Permanence values are defined to be between 0 and 1. -
distal-perm-init = 0.16- permanence value for new synapses on dendrite segments. -
distal-punish? = false- whether to negatively reinforce synapses on segments incorrectly predicting activation. -
global-inhibition = false- whether to use the faster global algorithm for column inhibition (just keep those with highest overlap scores), or to apply inhibition only within a column’s neighbours. -
inhibition-base-distance = 4- the distance in columns within which a cell inhibits all neighbouring cells with lower excitation. -
inhibition-speed = 2- controls effective inhibition distance. For every multiple of this distance away a cell is, its excitation must be exceeded by one extra active synapse for it to be inhibited. E.g. if this is2, a cell X, 6 columns away from Y, will be inhibited by Y ifexc(Y) > exc(X) + 3. -
activation-level = 0.03- fraction of columns that can be active (either locally or globally); inhibition kicks in to reduce it to this level. -
proximal-vs-distal-weight = 2- scaling to apply to the number of active proximal synapses before adding to the number of active distal synapses (on the winning segment), when selecting active cells. -
spontaneous-activation? = false- if true, cells may become active with sufficient distal synapse excitation, even in the absence of any proximal synapse excitation. -
alternative-learning? = false- if true, an extra learning step happens. Alternative predictions (i.e. depolarised cells) are carried forward an extra time step (as if the predicted cells were active); these forward-predicted cells learn on distal segments in the current context (as if they were active).
Anyway, I’m not sure how generally desirable the behaviour I described above is. I am sure that this is only a very superficial start at looking at generalisation.
As always, I value your advice.
–Felix
The code
The demo here was compiled from Comportex 0.0.4 with ComportexViz 0.0.4